


Dealing with Exactness
Differences in how machine learning models are trained

Brands thrive on the consistency of their messaging. Every brand has brand assets that are used over and over to ensure consistency across the assets they show the public. These are things like fonts, logos, and color palettes. Exactness is required in the usage of these assets in order to keep the brand running consistently and correctly. If the logo is slightly rotated or if the wrong font is used, there is a failure of brand messaging. That's why teams spend so much time reviewing content before it is released to ensure that it meets brand standards and provides a consistent message to the world.
In an ideal world, designers and marketers can use AI and machine learning (AI/ML) to improve their workflows. However, there is a rub when talking about exactness and AI/ML. Most systems using AI/ML are very bad at dealing with exactness. They are very good at finding similarities but not at enforcing pixel-perfect exactness. To understand why this is, we can look at how AI/ML models are trained.
Training an AI/ML system requires a lot of data, particularly when deep learning is used. Since data for certain concepts tends to be limited and the models are data-hungry, most machine learning engineers turn to various forms of data augmentation. In the data augmentation process, existing assets are modified to increase the amount of data available. In the data augmentation process, engineers will apply modifications such as flipping, rotation, cropping, adding noise, changing colors, or other filters to the initial asset. Variations of these values can result in creating 1000 images or more from a single image. This means that you can quickly obtain 1 million images for a data-hungry model from just 1000 assets. To see how this might work when building a model that can identify dogs, see the image below.
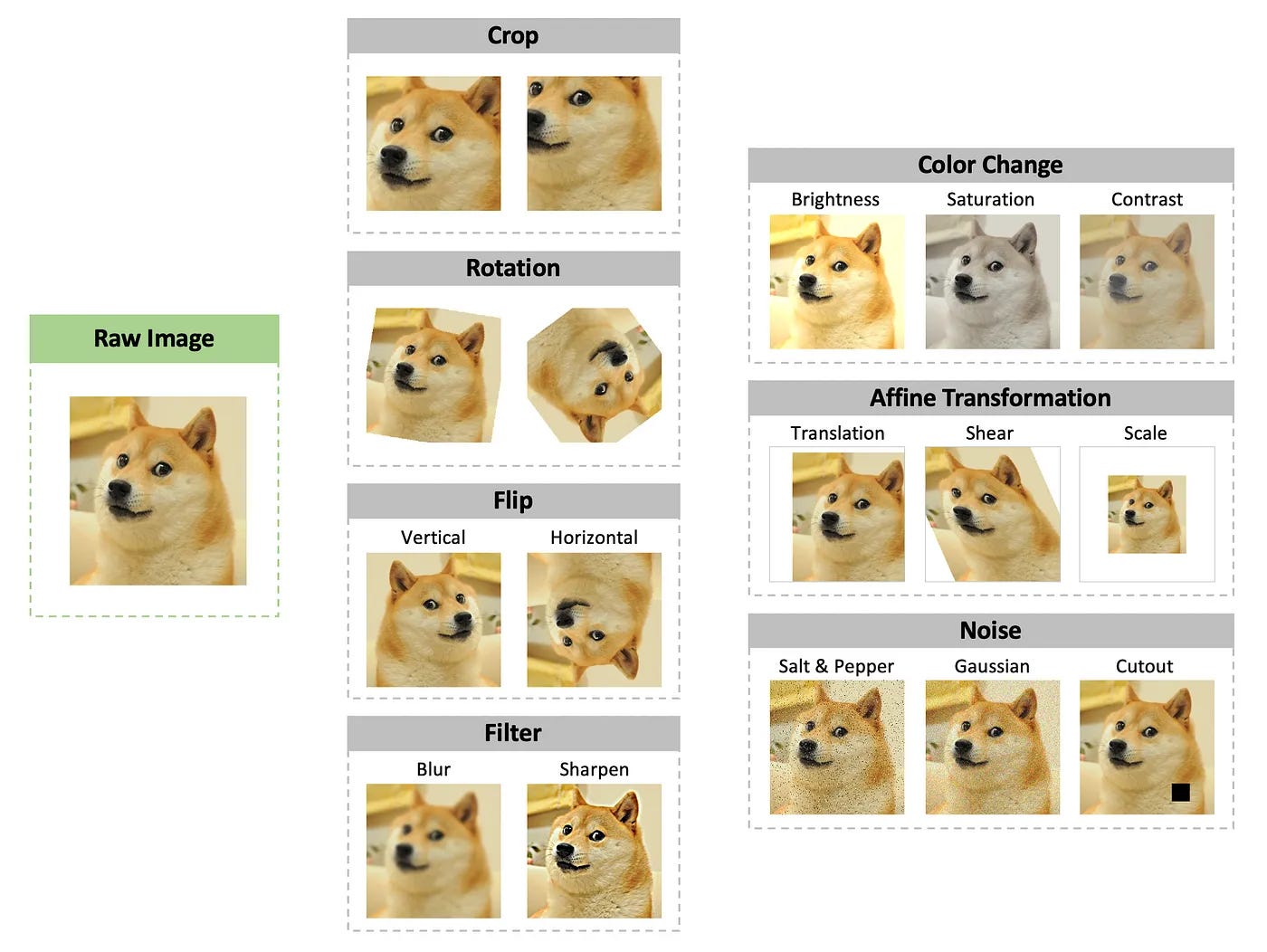
Figure 1. Examples of various forms of transformations used for data augmentation
While adding lots of modified images of dogs allows us to use a computer vision model to detect dogs in images, doing so is done at the expense of specificity. Computer vision models attempt to learn concepts, and they are trained to identify those concepts, such as dogs. What this means is that anything that appears to be a dog, whether from a face to a side view to a view from the top, will be picked up as a dog. For some use cases, this works extremely well, such as robots learning to navigate the world or when trying to help you tag a photo on social media. Unfortunately, this doesn't work for brands who require that their logo be used correctly. A brand manager doesn't want to see their logo from the side, rotated or distorted. Let's look at how this works in practice when a machine-learning model attempts to identify a logo.

Figure 2. Google's logo model identifying its own logo
Google's Cloud Vision model provides a way to identify logos in products. This can be seen in the image above. However, the model merely identifies the logo, but it does not know if the logo has been used correctly. All Google's model can tell you is if a logo is potentially present. It cannot make any determination about the exactness of usage. A brand manager would be irate if their logo was used in a slanted manner, but this machine learning model from Google can't tell you if that's bad.
Luckily, we at BrandGuard have developed an AI/ML model that can determine if a logo is being used correctly. We built this solving a different problem. Instead of attempting to identify the concept of a particular logo, we set out to build a model that would answer the question, "Has this logo been used correctly?". And it works very well. To understand how well it works, we put our model to the test against Google's logo model for the Tesla logo. Below you'll see an image with three values above. Class denotes if it is the correct logo or not, 1 (only the first image) is the correct logo, and 0 denotes an incorrect/distorted logo. We then provide output probabilities from our model and Google's model. The correct interpretation of these scores is that above 0.8 would be considered correct usage, and anything below 0.8 would be considered incorrect usage.

Figure 2. Identifying exactness between BrandGuard's logo models and Google Vision's logo models.
Looking across the composition, we can see that the BrandGuard model consistently identifies correct usage while the Google model consistently incorrectly identifies correct usage. This is based on the discussion about what each model is looking at.
For more information on BrandGuard or to sign up for a demo, please email contact@brandguard.ai or visit our website, www.brandguard.ai.